

-1.jpg?width=300&name=Untitled%20(3)-1.jpg)
If you’ve been paying attention to the technology trends of the past couple of years, you are almost certainly aware of the tidal wave of excitement around Generative AI and specifically Large Language Models (LLMs). The possibilities of real business solutions with these technologies have proven to be very legitimate and the barrier to entry is relatively low. Dataiku is strategically positioned as a platform for aiding in the development of Generative AI and LLM solutions. In this article, we'll explore a few examples demonstrating the potential of integrating the widely-used Python LLM library, LangChain, with OpenAI's API within Dataiku to produce natural language query (NLQ) solutions.
The Power of Large Language Models
Large language models like OpenAI's GPT-4 are exceptionally powerful, having been trained on extensive text data to generate human-like text in response to prompts. They excel in comprehending and generating coherent and contextually relevant text across various subjects, making them capable of answering questions, providing explanations, writing essays, creating poetry, and engaging in conversations. In a business context, these models prove invaluable for automating tasks, enhancing customer interactions, facilitating data-driven decisions, and boosting overall efficiency across different industries and functions.
One of the most exciting opportunities provided by LLMs for the enterprise is Natural Language Querying (NLQ). The goal of natural language query systems is to enable users to interact with data stores in an intuitive and user-friendly manner, making it easier for individuals without technical expertise to retrieve information or perform tasks. In the case of NLQ, LLMs are responsible for receiving a human-centric conversational question, translating it into machine-interpretable queries, retrieving the relevant data, and presenting it back in an interpretable and contextual response in English.
Generally, there are two approaches to NLQ development of private data using LLMs (think of “private” data as the data proprietary to your organization). The first approach involves “fine-tuning” a model with your data so the LLM itself “understands” your data and can provide immediate answers to questions. This approach is possibly the most comprehensive solution for answering questions on private data, but also requires a large amount of overhead and resources.
The second approach, which is generally the case when using LangChain, is what we’ll be covering in this article. In this approach, LangChain passes a meaningful prompt to a “generalized” LLM like OpenAI which contains contextual information about your private data. This allows the LLM to directly answer the question or respond with Python code or SQL statements that can help LangChain execute a function to generate the correct response, as shown in the following diagram.
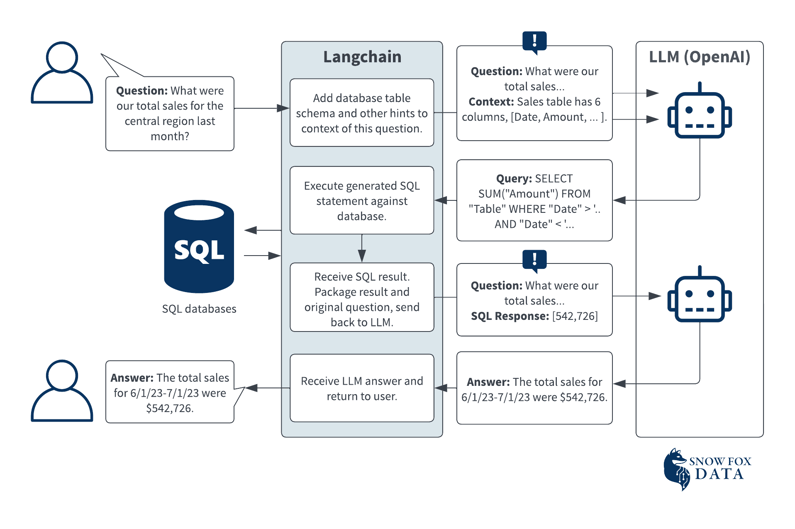 In this diagram, a user asks a question using natural language and LangChain forwards that question to an LLM, along with “contextual” information about the data sources available. This contextual information might be the schema as well as optionally a sample of the data contained in these sources. In this case, the LLM then generates a SQL statement that can be used to execute against the data source to determine the answer to the question. As you can see in the diagram, that SQL response is then fed back to the LLM by LangChain and a full English sentence is generated in response to the user.
In this diagram, a user asks a question using natural language and LangChain forwards that question to an LLM, along with “contextual” information about the data sources available. This contextual information might be the schema as well as optionally a sample of the data contained in these sources. In this case, the LLM then generates a SQL statement that can be used to execute against the data source to determine the answer to the question. As you can see in the diagram, that SQL response is then fed back to the LLM by LangChain and a full English sentence is generated in response to the user.
In this article, we won’t be showing an example of the SQL data source use case as shown above, but it’s very possible to utilize database sources using LangChain’s SQL capabilities.
Introducing LangChain
One way to get a taste of some of the NLQ capabilities of large language models is by using one of the most popular open-source Python LLM libraries today, LangChain. LangChain is an open-source framework tailored for the development of applications driven by language models. Its purpose is to streamline the creation of such applications by providing a toolkit and abstractions that facilitate the seamless integration of language models with various data sources, enable interaction with their surroundings, and support the construction of intricate applications.
Our examples will show LangChain development inside of Dataiku and integration with Dataiku datasets and folder content. Those who use Dataiku will certainly appreciate the flexibility that the DSS platform provides to allow for preparation and analysis of a dataset which can then be integrated into this type of advanced solution. These demos will illustrate the ability to ask questions of data using natural language, utilizing the power of the OpenAI API.
Using Langchain + OpenAI in a DSS Notebook
The project, code, datasets, and code environments used in this article are available as a Dataiku project file download.
Creating the Code Environment
In order to get started, it is first necessary to create a new Python Code Environment with the packages that we’ll want to develop. If you’re not familiar with creating Code Environments in Dataiku, you’ll find more information in their DSS 12 documentation or by navigating to the “Administration” “Code Envs” section of the DSS user interface. For this example, we’re going to create a Python 3.9 environment with the following packages:
langchain
openai
pypdf
chromadb
tabulate
tiktoken
In this package list, you’ll notice the LangChain and OpenAI Python packages, as well as some others that will be utilized to interface and store data that we’ll be using in our examples.
To expedite this process, you’ll also find an exported environment file in the above Github repository which you can import directly into your DSS instance.
Importing the Project
Once you have a code environment imported or created, you should be able to smoothly import the Dataiku project, ignoring any plugin warnings that may appear. Inside this project’s flow, you’ll find a single “internal” dataset containing the accessible job logs from your DSS instance, as well as a managed folder containing PDF files. These PDF files are purely for demonstration purposes from the Library of Congress but represent what could be an internal knowledge base at your organization. 
Exploring the Code
In the “Notebooks” section of the project, you’ll find a Python notebook containing the code that we’ll be following in the subsequent sections. You will be able to run this code in your notebook and modify the queries to experiment with more advanced possibilities.
LangChain Setup
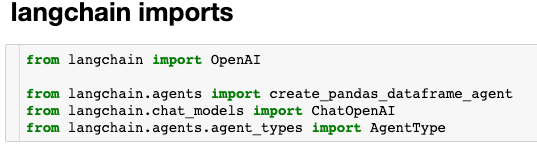
In this notebook, we’ve broken the code into cells which provide some logical groupings for the contained functionality. The first block should look very familiar, with a few standard Dataiku and standard Python data libraries. The second block contains the set of LangChain and OpenAI libraries that we’ll be working with for our first integration.
 In the next block of code, you’ll see that we’re setting an OpenAI API key as an environment variable. If you’d like to run these demos, you’ll need to set this to your API key. If you haven’t created an Open API key already, there are some good instructions on how to do so in articles like this one.
In the next block of code, you’ll see that we’re setting an OpenAI API key as an environment variable. If you’d like to run these demos, you’ll need to set this to your API key. If you haven’t created an Open API key already, there are some good instructions on how to do so in articles like this one.
 In other LangChain examples, you may see alternative methods to set this API key. For Dataiku specifically, the above os.environ call is the preferred method, and you may experience challenges with other alternatives.
In other LangChain examples, you may see alternative methods to set this API key. For Dataiku specifically, the above os.environ call is the preferred method, and you may experience challenges with other alternatives.
Dataiku Dataset Source
The purpose of this exercise is to allow for natural language querying of some of the datasets we have connected to from Dataiku. In the case of the Dataiku Jobs dataset we’ve added to this project, it will allow us to answer a question like “Who ran the last job?” or “When was the last failure in my project?” using natural language. In the next code block, we’re going to get a reference to the dss_jobs dataset in our project flow, and then use that reference to obtain a Pandas DataFrame - a procedure you’ve likely seen numerous times if you’ve worked with Dataiku notebooks in the past. 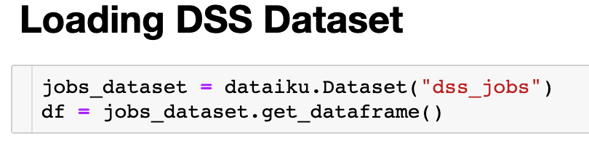 Now that we have a DataFrame in memory, we will make use of the create_pandas_dataframe_agent method from the LangChain library. As you’ll see in the following figure, using this method, we can specify a language model to use and in this case, we’re creating a new GPT-3.5-turbo OpenAI model.
Now that we have a DataFrame in memory, we will make use of the create_pandas_dataframe_agent method from the LangChain library. As you’ll see in the following figure, using this method, we can specify a language model to use and in this case, we’re creating a new GPT-3.5-turbo OpenAI model.
The result of this method call is a LangChain “Agent” which is capable of performing complex interactions between the Pandas Dataframe and the specified LLM. Generally, LangChain agents rely on an LLM to determine their actions and their order, learning from past actions to guide future choices. These Agents can link up and connect the LLM to outside knowledge or tools for calculations and if there's a mistake, they try to correct it.
With that simple setup, we can now use the Agent to interact with the Pandas DataFrame extracted from our Dataiku Dataset using the agent.run method. In the next diagram you’ll see that we’ve asked the Agent “What kinds of data does this dataset contain?” - and the LLM is able to give an incredible answer considering we’ve supplied no further “data definition” information to the LLM. Always remember that unchecked answers provided by LLMs can provide a potentially misleading analysis. It’s extremely important to consider this possibility when designing solutions and “human in the loop” validations are currently an integral part of production LLM solutions.
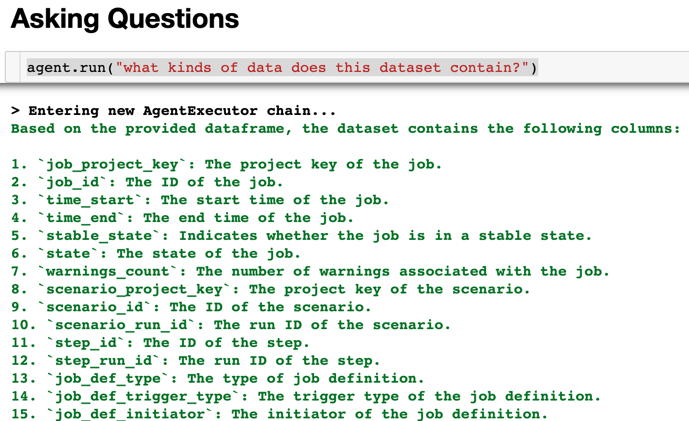 As it turns out, the descriptions provided by the LLM are very accurate for the majority of the columns - with the exception of the job_def columns (it gave a good guess, a human might not know those either without digging deeper). A pretty exciting result for just a few lines of code!
As it turns out, the descriptions provided by the LLM are very accurate for the majority of the columns - with the exception of the job_def columns (it gave a good guess, a human might not know those either without digging deeper). A pretty exciting result for just a few lines of code!
Let’s try running another question, this time more focused on the DSS job data itself- “When was the most recent failed job? What was the project key of that job?” You’ll notice that in this case, we’re also providing multiple questions in a single prompt, requiring the Agent to process some more complex interactivity.
Again, we see a perfectly accurate answer to the question telling us the time of the most recently failed job and the project key of that job. In this case, we get a glimpse of a more complex, multi-step interaction between the Agent and the LLM. In the first step of this interaction, LangChain queries the DataFrame to find the most recent failure, and then it takes that result and performs a second query to find the corresponding project key.
As we’ve seen in this example, connecting an existing Pandas DataFrame to LangChain and using an LLM to query it is a very easy setup. You can imagine how tricky it would have been to manually write the Python code to answer those same questions, especially for someone not familiar with the Pandas nuances. You can find additional information regarding LangChain and Pandas interaction (including multiple joined DataFrames) in the reference material.
Dataiku Managed Folder as a PDF Source
In this next example, we’re going to expand upon that capability to include a less structured data source - PDF files contained in a Dataiku-managed folder.
Slightly more complex than the previous Pandas example, the setup for using LangChain to perform question answering over documents involves an additional step of creating an “index” of the documents to be queried which is typically stored as vector embeddings in a vector database (technical details of vector databases is beyond the scope of this article but a great overview can be found in this LangChain book). At a high level, this entire process is often referred to as retrieval-augmented generation (RAG).
The first step we’ll take in our Python notebook will be to iterate through the PDFs stored in our Dataiku managed folder and create the index mentioned above. To do this, we’re going to make use of the LangChain PyPDFLoader class which will greatly assist with the steps needed to process a PDF file into text chunks, which is necessary to create our vector index. In the following code, we’re using the Dataiku API to obtain a reference to the PDFs folder, and then storing a list of “loader” objects which can be used to create our vector database.

With these loaders available, LangChain provides a simple VectorstoreIndexCreator class which makes it easy to populate a vector database from the loaders.
 Behind the scenes, the VectorstoreIndexCreator is performing several tasks, each of which is configurable through additional parameters:
Behind the scenes, the VectorstoreIndexCreator is performing several tasks, each of which is configurable through additional parameters:
- Splitting documents into chunks
- Creating embeddings for each document
- Storing documents and embeddings in a vector store
We are not specifying any vector database connection information in this section because, by default, LangChain uses the Chroma in-memory database as the vector store to index and search embeddings.
Because LangChain makes this process so seamless, with just these few lines of code we’re already prepared to start querying our PDF sources. You’ll see that the answers below align perfectly with the text from the PDFs.



As you can see in these query examples, it’s now possible to answer questions over a large amount of potentially complex PDF text without writing more than a few lines of code. Although this is a small-scale example, this same approach can be applied to a much larger scale to provide insights into an entire internal knowledge base.
Exposing the Power of Large Language Models in Dataiku
We’ve seen through these examples how easy it is to provide NLQ using LLMs with internal sources of data - which could range from PDF documents to database tables or flat files. The code that we’ve written could be easily transferred into a web application, shared library, API or recipe, or plugin within Dataiku. Because this integration is relatively easy, it can free up your development time to focus on higher-value topics such as the integration of this capability into end-user applications. Some ideas for application integration that we’ve implemented using very similar LangChain code in Dataiku are:
- Custom web applications
- Dataiku web apps
- SMS integrations through a Dataiku API
- Amazon Alexa integration through a Dataiku API
- Dataiku dataset processing plugins
Any of these integrations can put a vast amount of power and flexibility into the hands of end-users in ways that were previously impossible (or at least very difficult) and can help break down data silos within your organization.
Endless Opportunities With Large Language Models
In this article, we’ve covered a brief overview of the possibilities of using large language models for business use cases using natural language querying capabilities. These opportunities are made exceptionally accessible because of open-source libraries such as LangChain and a comprehensive development platform like Dataiku.
For leaders exploring Generative AI, NLQ can be a great initial step. NLQ use cases can be put into production quickly by only utilizing one table of data and establishing simple prompts. If you’re a leader considering getting started with AI, take a look at our suggestions for the first steps to get you started.
